
オフコンからの抽出データをC言語で文字コード変換
最近、ホストシステムからデータ移行する開発を引き継ぎました。具体的には三菱電機のオフコンからのデータ移行です。
目次
オフコンとは
40年前?コンピュータシステムといえば、IBMのホストコンピュータ(メインフレームとも呼ばれていました)を筆頭に、富士通、NEC、バロース等があり、その後小型化したコンピュータ(オフコン)、つまりオフィスコンピュータが使われてきました。
文字コードについて
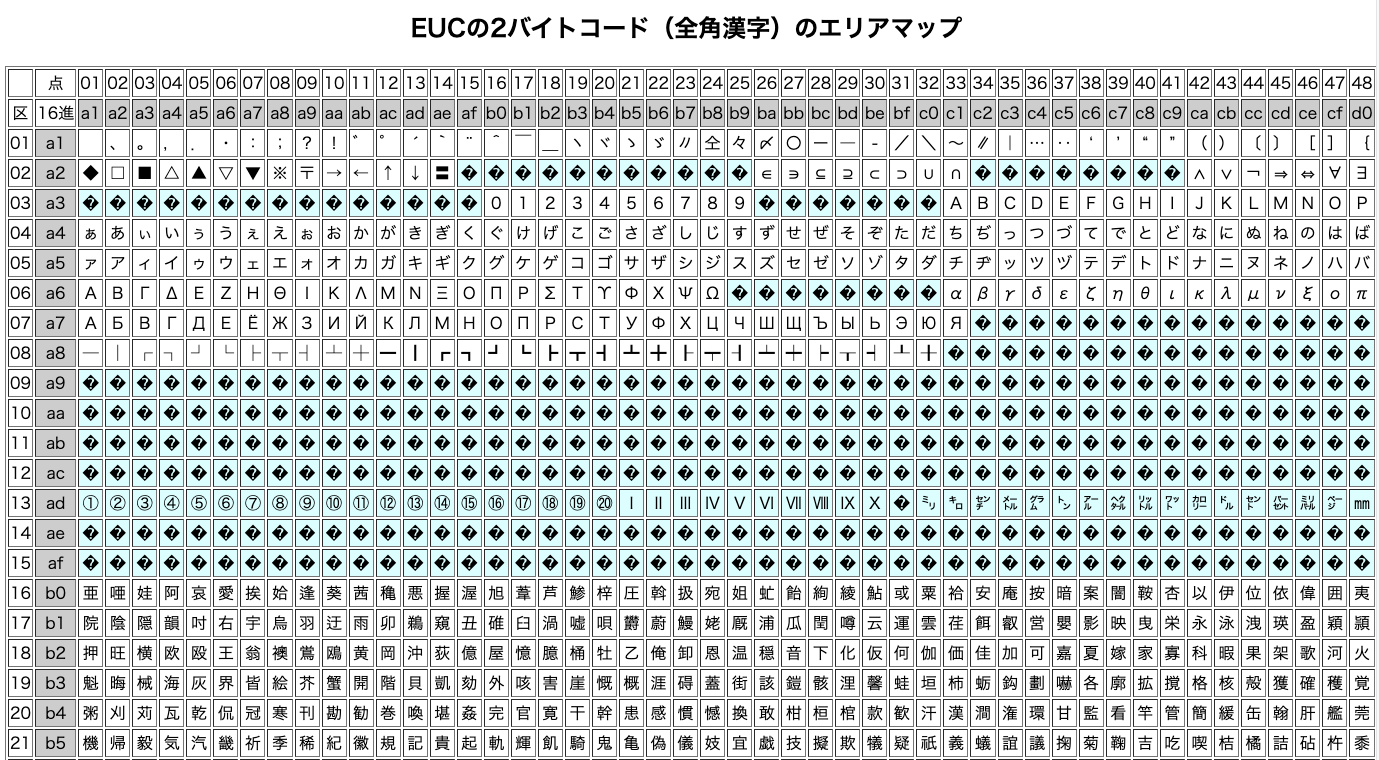
文字コードは、1バイト系はEBCDICコードでアルファベットの大文字、小文字、数字、記号及び制御コードのmax256文字です。三菱電機のオフコンは日本語用にアルファベットの小文字を半角カナに変えたカナ用EBCDIC、漢字コードはJEF漢字コードを使用していました。JEF漢字コードはEUC漢字コードと基本的には同じですが、全角空白が半角空白(0x40)2個のコードとなっており、またEUC漢字コードの2バイト系の半角カナは未使用です。
引き継ぎ時点での内容
オフコンから抽出したデータをコード変換し、新システムにimportするCSVファイルの作成をとある会社に依頼していました。私の預かり知らない1年以上前のことです。
新システムにimportするとマスタ系の社名、略称、納入先名等に文字化けが多々あり、受注データや出荷データには件数は少ないですが項目内容が明らかに違うデータもありました。
ホストシステムから移行した場合文字化けする原因
文字化けは一般的に下記のような原因があります。
- 漢字1文字の(株)を含む外字コード群
- 文字列の中の ,(カンマ)や”(ダブルクォーテーション)
文字化けの大半は1文字(2バイト)の(株)でした。続く文字によっては(株)以降が全て文字化けし跡形もない名称もありました。同じように外字は(有)(資)があり計3文字でしたが、なぜか2種類のコードで外字登録されており、計6文字が文字化けの第一原因でした。外字については資料が何もないので取り敢えず文字化けから判断しました。
ホストデータの確認
ホストデータの内容を確認するには(社内の開発はMacBook Proなので)ターミナルかVSCodeのターミナルでxxdコマンドを使用します。下図のように16進イメージで確認出来ます。20数年前UNIXでは odコマンドで確認していましたがコマンドが違っていました。Windowsでは「秀丸」エディタで確認が出来ます。
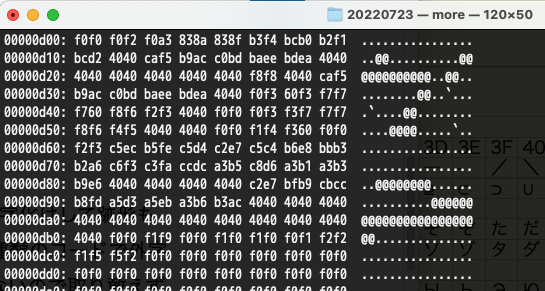
xxd(バイナリーを16進数で出力)の見方
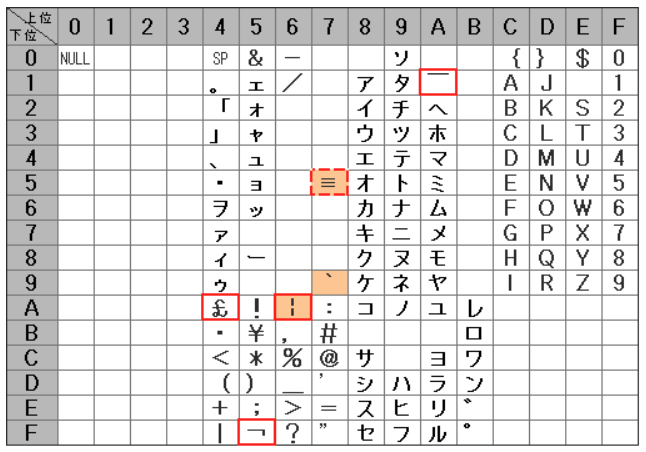
1バイトを0,1,2,,,,a,b,c,d,e,f 16進2文字で表示します。まず1行目のf0f0 f0f2 f0a3 …先頭5バイトは(引き継ぎ資料の定義書から)9タイプ(数字)で得意先コード、EBCDICコード表(下図)を確認すると00020 と分かります。コード表は横(上位)、縦(下位)の順で見ます。f0は1行目の右端にあります。
次に11バイト目から32バイトは漢字タイプで得意先名、b3f4 bcb0 b2f2 bcd2 4040 caf5…. EUC漢字コード表を縦横に見ると「株式会社(空白)宝」と分かります。4040は全角の空白です。
EUC漢字コードの見方
EBCDICコード表とは反対で縦(左端)のb3を探し、その行の横列(上段)のf4と交差した文字探します。1文字目は「株」が確認できます。EBCDICコード表と違い文字数(縦横)が多いためブラウザを縦に横にスクロールさせる必要があり、その際左端と上段のコードが見れなくなり探しにくいと思います。下図で「株」見えません。
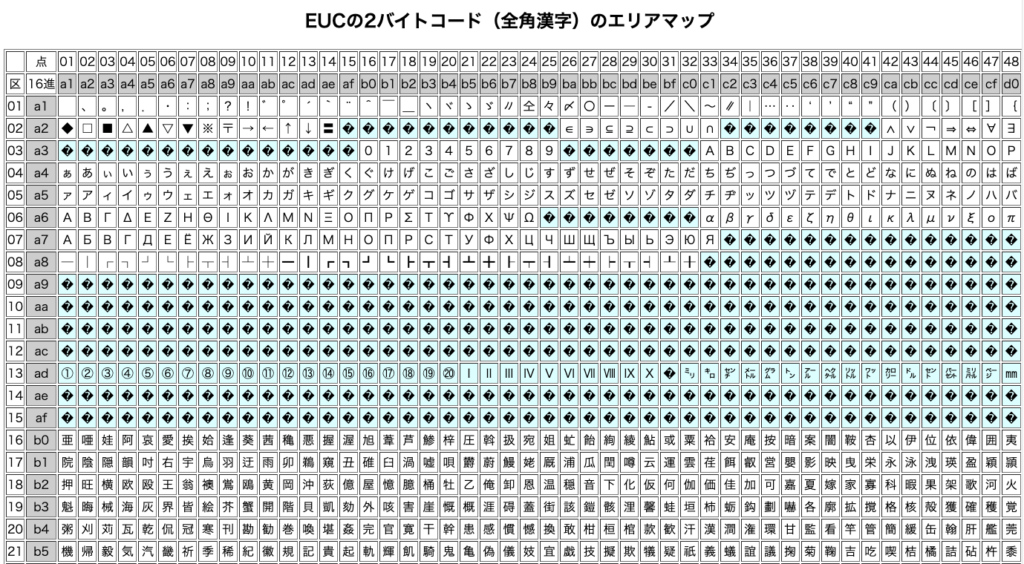
更に43バイト目から16バイトは略称です。43バイト目は、3行(2行で32バイト)目の11バイト目からとなりますから、f8f8 4040 caf5 …. EUC漢字コード表で見ると、f8f8は該当文字なし(外字コード帯)、4040は空白、caf5は「宝」。
会社名「宝」と株式会社から推測するとf8f8は、1文字の(株)と思われます。とまァこんな感じで確認しますが結構大変です。
その他の原因
出力されたCSVファイルは,(カンマ)区切りの文字列を”(ダブルクォーテーション)で囲っていないために、文字列の中にある,(カンマ)を区切り文字と判断してセルずれを起こしたデータがありました。これが内容違いの項目の原因でした。
また、文字列の中にインチ記号の代わりに”(ダブルクォーテーション)が使われていましたが、”(ダブルコーテーション)で囲っていないためそのまま出力されOK?、文字列を”(ダブルコーティション)で囲む場合はもう一つ”(ダブルクォーテーション)を(正確には前に)追加してエスケープする必要がありますが、、たまたま上手くいっていたケースでした。
コード変換プログラムを作成
文字化けが解決しそうにないので、20数年前までに40社ほどホストシステムから移行したことを思い出してC言語でコード変換プログラムを作成することにしました。
プログラム概要を整理
- ホストファイル(19種類)の(レコード)定義書確認(先の会社が作成していました)
- ホストファイルはデータ(レコード)分割されておらず1ファイルが1データのイメージなのでfgetsではなくfseekでレコード長分づつ読み込む
- 1バイト文字は、半角カナを含めてEBCDICからACSIIコードに変換
- 2バイト文字は、半角カナを含まないEUC漢字コードからJIS漢字コードに変換し、更にSJIS漢字コードに変換
- 項目単位に”(ダブルコーテーション)で囲んだCSVファイルを作成
- 最後にsystem()にて nkfを実行して全体をSJISからUTF-8に変換
ホストデータの読み方
下記のように、全体のファイルサイズを取得しレコード長で割りデータ件数を取得します。それをfseekで先頭から1件づつread-pointをずらしながら件数分for-loopで読込みます。fseekの3番目の引数(移動原点)にSEEK_CUR(現ファイル位置)を指定すると、読み込んだend-pointから次のレコードを読めるので特別な処理は不要です。テキストデータを改行コード単位で読み込むfgets とは随分と異なります。
ftell(G_fp1); // ファイルサイズ取得
loop_cnt = file_size / gFlen;
printf("file_size=%lu loop_cnt=%d\n", file_size, loop_cnt);
fseek(G_fp1, 0, SEEK_SET); // ファイル先頭に移動
for (i=0; i<loop_cnt; i++) {
memset(fBuf, '\0', sizeof(fBuf));
fseek(G_fp1, 0, SEEK_CUR); // ファイルの現在位置から
fread(fBuf, gFlen, 1, G_fp1); // レコード長分、1件読むEBCDICとASCIIの変換
変換に必要なコードについて対比表を以下のように作成します。それぞれ16進表記で記述し肝心なのはunsigned char、つまり1文字のcharではなく数値として扱います。
static struct ebc_ascebc_tbl { /* EBCDIC, ASCII 対応 TBL */
unsigned char ebc;
unsigned char asc;
} T_cnv[CNV_MAX] = {
0x40, 0x20, // SP
0xf0, 0x30, // 0
0xf1, 0x31, // 1
0xf2, 0x32, // 2
この表(table)を利用してEBCDICコードを渡して、ASCIIコードをreturnします。
static unsigned char C_cnv_ebc_to_asc(chr)
unsigned char chr;
{
int i;
for (i=0; i<CNV_MAX; i++) {
if (chr == (unsigned char)T_cnv[i].ebc) {
return((unsigned char)T_cnv[i].asc);
}
}
/* 変換TBL以外は、0x00 */
return ((unsigned char)0);
}EUC漢字コードからJIS漢字コード変換
EUCからJIS変換は、2バイトのそれぞれのバイトのハイビットを0にすればOKです。
例えば「永」はEUC漢字コードでは16進でb1ca、2進で1011 0001 1100 1010ですから、0011 0001 0100 1010 になればOK、16進では314aです。
c言語的には 0x7fを加算(& 0x7f)します。ハイビットを0にする、分かりましたか?
また外字(株)は前後に半角カッコを追加し、株のJISコード(0x33, 0x74)を強制的に入れ文字化け対策します。これで4バイトになりますが、外字ではないのでJISでもSJISでもUTF-8でも変換OKです。
if (c1 == 0xf8 && c2 == 0xf8) { /*(株) */
*(out_p+out_cnt) = 0x4a; /* ( */
*(out_p+out_cnt+1)= 0x33;
*(out_p+out_cnt+2)= 0x74;
*(out_p+out_cnt+3)= 0x4b; /* ) */
pos += 2; /* 入力位置 */
out_cnt += 4; /* 出力位置 */
continue;
}JISからSJIS漢字コード変換
JIS、SJIS間は変換ルールがあり1バイト目が奇数か偶数か判断して0x1fを加算するか0x7eを加算する、更に、、、と書いても分かりにくいですから、下記のようなコードを書きました。割と簡単です。
/*----- 2バイト目のコード変換 -----------------*/
if ((c1 & 1) != 0) { /* 1バイト目 奇数 */
c2 += 0x1f;
if (c2 >= 0x7f)
c2++;
} else { /* 1バイト目 偶数 */
c2 += 0x7e;
}
/*----- 1バイト目のコード変換 -----------------*/
c1 = (c1 - 0x20 - 1);
c1 = (c1 / 2) + 0x81;
if (c1 >= 0xa0) /* 第2水準漢字 */
c1 += 0x40;SJISからUTF-8変換
SJISからUTF-8の変換は、Macの変換ツールnkf をC言語のsystemから実行しました。
また、移行環境はWindowsPCなのでWindows版に移行しました。違いはSJIS、UTF-8変換がnkfではなくnkf32.exeの違いのみです。
Windows環境でコード変換検証
19種類のファイルをコード変換し確認しているなんと文字化けしているファイルが有りました。
調査をすると文字列(漢字項目)の中に、EBCDICでは入力出来ないような 0x0a、つまりASCIIの改行コードに該当する文字が含まれていました。MacはOKなのになぜ??
ホストデータをfseekで読む際、fopenをバイナリーモードではなく、テキストモードでopenしていたのが原因でした。fopen(sGetFileId, “r”)をfopen(sGetFileId, “rb“)に変更してOKとなりましたが、、、正確な原因を確認したい、、、
Macの場合は通常のr(テキストモード)でopenすると0x0a(¥n)を改行コードと認識しますがそれをfseekで読み(漢字コード、外字コード帯以外は空白として)文字化けとならず、Windowsでは r(テキストモード)でopenすると改行コードが0x0d,0x0aの2バイトのため不足の0x0d(¥r)をopen時に追加してくれているようで、1バイトづつずれて文字化け起こしていました。
完成
原因もわかりこれでスッキリとホストデータのコード変換、CSV出力が完成となりました。
最近大半はPHPで開発しており、20年振りにC言語でプログラムを書きました。PHPの良いところとC言語しか出来ないことを再認識しました。